第13章 様々な魔方陣の作成および自動生成
第14話 1列数独の構造解析

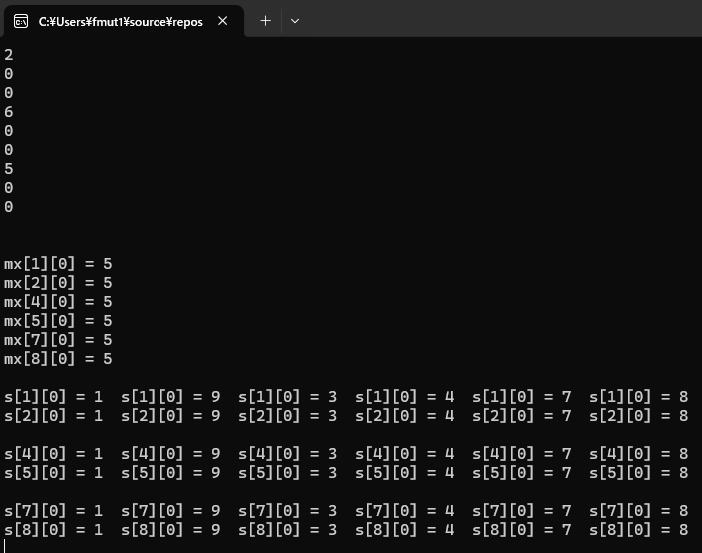
1列数独を構造解析するプログラム例
マルチスレッド版数独自動生成ソフトC++コードを題材とする超初心者のためのVisual Studio C++講義
第13章 様々な魔方陣の作成および自動生成
第14話 1列数独の構造解析
1列数独を構造解析するプログラム例
#pragma warning(disable: 4996)//第2編のために必要
#include<iostream>//インクルードファイルiostreamの読み込み
#include<conio.h>//while(!_kbhit());を使うためのお呪い
#include<string> //文字列変数を使えるようにするために組み込む
#include <iomanip> //setprecisionを使えるように組み込む
#include <cmath>//powなどを使うときに必要
#include <ctime>//time()(←現時刻発生する関数)を使うために必要
using namespace std;//coutを使うときに必要なお呪い
#include <process.h>//_beginthreadを使うために必要
void 全体構造解析関数();//スレッドを派生させる関数
const int n = 9;//数独の一辺は9です
int s[n][n][n];//各空欄の候補数字を収納する3次元配列
int a[n][n];//問題及び解答を収納する2次元配列
int mx[n][n];//各空欄の候補数字数
int main() {
//すべてを0に初期化
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
a[i][j] = 0;
}
}
//データ入力
a[0][0] = 2;
a[3][0] = 6;
a[6][0] = 5;
for (int i = 0; i < n; i++) {
cout << a[i][0] << endl;
}
cout << endl;
cout << endl;
全体構造解析関数();
while (!_kbhit());//待機させるための命令
return(0);
}
void 全体構造解析関数() {
int 配列[9] = { 1,2,3,4,5,6,7,8,9 };
int max = 8;
for (int i = 0; i < n; i++) {
if (a[i][0] > 0) {
// a[i][0] を候補から除外
for (int j = 0; j < max; j++) {
if (配列[j] == a[i][0]) {
配列[j] = 配列[max];
配列[max] = a[i][0];
max--;
break;
}
}
}
}
for (int i = 0; i < n; i++) {
if (a[i][0] == 0) {
mx[i][0] = max;
for (int j = 0; j < n; j++) {
s[i][0][j] = 配列[j];
}
}
}
for (int i = 0; i < n; i++) {
if (a[i][0] == 0)cout << "mx[" << i << "][0] = " << mx[i][0] << " " << endl;
}
for (int i = 0; i < n; i++) {
if (a[i][0] == 0) {
for (int j = 0; j < mx[i][0] + 1; j++) {
cout << "s[" << i << "][0] = " << s[i][0][j] << " ";
}
}
cout << endl;
}
}
実行結果
実行結果については解説が必要です。
1行数独のときと同じで1列数独でも候補数字群が同じになります。
パズルの絶対条件である答が一つのいう条件を
1行数独・1列数独では満たしません。
全行・全列・全ブロックがそろうときに唯一解になりますし、
理詰めで解ける数独になります。
ですから、1列数独という名称は仮のもので、
1行や1列や1ブロックではパズルの絶対条件である答が1つであるを満たさないのです。
全体構造解析をいきなりやったのでは4次元繰り返し処理または5次元繰り返し処理になり、
これは初心者では当然無理な課題です。
最終的には全体構造解析をしなければならないにしても、
全体構造解析とは部分構造解析の総和です。
部分構造解析とは1つのセルに数字を入れたときに影響を与えるセルについて解析する事を指しています。
問題を作る過程で同じ行または同じ列または同じブロックで数字の重複が起きれば、
当然数独は解なしになり問題は成立しません。
ですから、1つ数字を入れるごとに影響与える部分について解析するのが部分構造解析です。
問題作る過程や問題を作る過程で同じ行または同じ列または同じブロックで数字の重複が起きないようにするには、
数字を入れる度に構造解析すなわち部分構造解析をしていけばよいのです。
なぜなら、重複が起きれば候補数字数0という現象がおきます。
部分構造解析をやって候補数字数が0は問題制作途中で数字の重複が起きていることを教えてくれます。
候補数字数 = mx[i][j]が0になってしまえば当然問題は解のない問題になります。
部分構造解析をやってmx[i][j]が0の時点で今いれた数字は入れられないことがわかります。
部分構造解析は、問題を作る過程でも必要ですが、
問題を解いていく過程でも常に部分構造解析をしなけばなりなりません。
工夫して4次元繰り返し処理に落とすことができたとしても、
実際には数字を入れる度に構造が変わっていきますので、
時間を考慮に入れれば実際上は5次元繰り返し処理になります。
5次元動的繰り返しになるわけですが、
動的(時間とともに変わるという意味)処理については、
毎回部分構造解析をやっておけばクリアできるのです。
さて、次話への課題です。
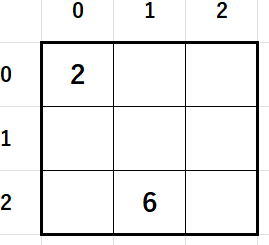 について構造解析をやってください。
について構造解析をやってください。
つまり、1ブロック数独です。
第13章第13話へ 第13章15話へ
本講義トップへ