両者共に1250回版では差が出なかったので1250000回版にして実験しました。
実験結果
4スレッド版

比較のために両じけっ兼結果をまとめると、
シングル版
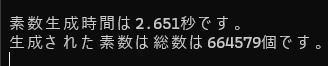
4スレッド版
2.651÷0.902 = 2.939
約3倍の速度が得られました。
4倍にならないのはスレッドを起動するに少し時間がかかるからです。
実験回数を増やせば増やすほど4倍に近づいていきますが、
4倍にはなりません。
実験するときには表示部分は外しておいた方がよいでしょう。
表示に時間がかかるからです。
マルチスレッド版数独自動生成ソフトC++コードを題材とする超初心者のためのVisual Studio C++講義
第11章 マルチスレッドプログラミング
第8話 マルチスレッドコードと両コードによる実験結果
4スレッドコード
#pragma warning(disable: 4996)//第2編のために必要
#include<iostream>//インクルードファイルiostreamの読み込み
#include<conio.h>//while(!_kbhit());を使うためのお呪い
#include<string> //文字列変数を使えるようにするために組み込む
#include <iomanip> //setprecisionを使えるように組み込む
#include <cmath>//powなどを使うときに必要
#include <ctime>//time()(←現時刻発生する関数)を使うために必要
using namespace std;//coutを使うときに必要なお呪い
#include <process.h>//_beginthreadを使うために必要
void 変身の術関数(void* aa);//スレッドを派生させる関数
int 素数判定(int x);//素数判定関数
const int th = 4;
int 継続[th] = { 1,1,1,1 };
int s[4][400000];//8 * m + 2 * a + 1 タイプの素数を収納する
int cn[4] = { 0,0,0,0 };//8 * m + 2 * a + 1 タイプの素数をカウントする変数
int main() {
clock_t hj, ow;
hj = clock();
int ii[th];
for (int i = 0; i < th; i += 1) {
ii[i] = i;
_beginthread(変身の術関数, 0, &ii[i]); //新しいスレッドを起動して、そのスレッド上で関数問題生成関数を働かせなさいの命令
}
while (1) {
int 合計 = 0;
for (int i = 0; i < th; i++)合計 += 継続[i];
if (合計 == 0)break;
}
ow = clock();
cout << 2 << endl<<endl;
for (int i = 0; i < 4; i++) {
for (int j = 0; j < cn[i]; j++) {
cout << s[i][j] << " ";
}
cout << endl << endl;
}
cout << "素数生成時間は" << (double)(ow - hj) / CLOCKS_PER_SEC << "秒です。" << endl;
cout << "生成された素数は総数は" << cn[0] + cn[1] + cn[2] + cn[3] + 1 << "個です。" << endl;
while (!_kbhit());//待機させるための命令
return(0);
}
void 変身の術関数(void* aa) {//マルチスレッド
int a = *(int*)aa;
for (int i = 0; i < 1250000; i++) {
if (素数判定(8 * i + 2 * a + 1) == 1) {
s[a][cn[a]] = 8 * i + 2 * a + 1;
cn[a]++;
}
}
継続[a] = 0;
}
int 素数判定(int x) {//素数判定関数
if (x == 1)return(0);
if (x == 2)return(1);
if (x % 2 == 0)return(0);
int 最後 = sqrt(x);//割り算をする最後の数字
for (int i = 3; i <= 最後; i++) {
if (x % i == 0)return(0);
}
return(1);
}
両者共に1250回版では差が出なかったので1250000回版にして実験しました。
実験結果
4スレッド版
比較のために両じけっ兼結果をまとめると、
シングル版
4スレッド版
2.651÷0.902 = 2.939
約3倍の速度が得られました。
4倍にならないのはスレッドを起動するに少し時間がかかるからです。
実験回数を増やせば増やすほど4倍に近づいていきますが、
4倍にはなりません。
実験するときには表示部分は外しておいた方がよいでしょう。
表示に時間がかかるからです。
表示は「人間のための処理」なので、とても時間がかかります。
今回は「CPUがどれだけ計算したか」を比べたいので、
いったん表示を止めて“計算だけ”の時間を測ります。
参考までにそれぞれの版のCPU使用率も載せておきます。
シングル版
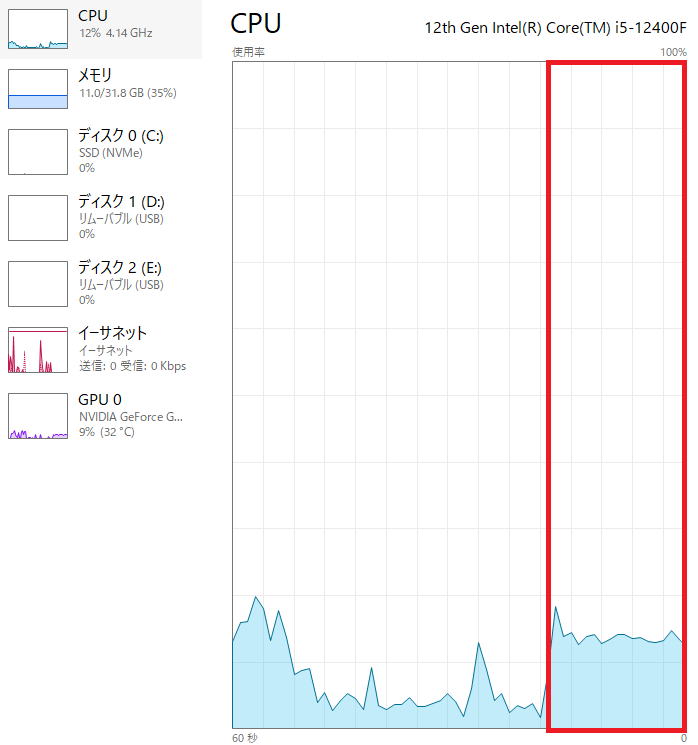
約12%です。
それに対して4スレッド版は
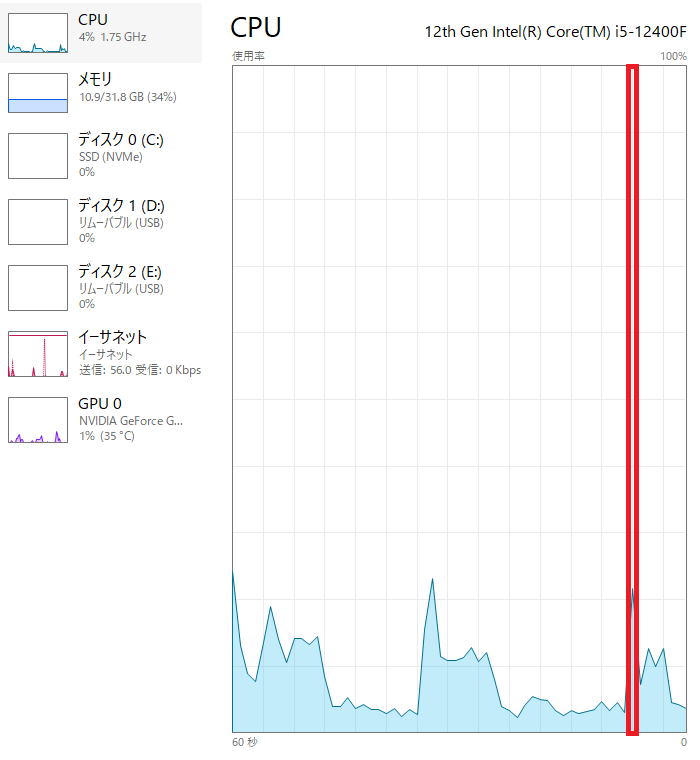
一瞬で終わってしまうので測定は難しかったのですが、約25%です。
CPU使用率で言うと約2倍です。
さて、速さにして約3倍の違いはなぜ発生したのでしょうか。
両者の違いはシングル
hj = clock();
素数生成1();//8 * m + 1 タイプの素数を生成
素数生成2();//8 * m + 3 タイプの素数を生成
素数生成3();//8 * m + 5 タイプの素数を生成
素数生成4();//8 * m + 7 タイプの素数を生成
ow = clock();
対して4スレッド版
hj = clock();
int ii[th];
for (int i = 0; i < th; i += 1) {
ii[i] = i;
_beginthread(変身の術関数, 0, &ii[i]); //新しいスレッドを起動して、そのスレッド上で関数問題生成関数を働かせなさいの命令
}
while (1) {
int 合計 = 0;
for (int i = 0; i < th; i++)合計 += 継続[i];
if (合計 == 0)break;
}
ow = clock();
という違いがあります。
素数生成1();//8 * m + 1 タイプの素数を生成
素数生成2();//8 * m + 3 タイプの素数を生成
素数生成3();//8 * m + 5 タイプの素数を生成
素数生成4();//8 * m + 7 タイプの素数を生成
は順番にやるしかありません。
世界が一つしかないからです。
ですが、マルチスレッドでは4つの処理が同時に行っています。
4つのスレッドを派生させるとは、
4つの異世界を発生させることです。
4つの異世界はルートスレッドが属する世界と並行世界です。
ルート合わせて5つの並行世界が立ち上がっています。
今回はルートスレッドに待機させているだけで仕事をさせていませんから、
4つの異世界のみが素数を生成する仕事をしています。
ポイントは同時に異世界が仕事をしていることです。
スレッド立ち上げるのに多少時間がかかりますので、
4倍にはなりませんでしたが、
仕事の量が増えるとスレッドを起動する時間など誤差範囲になっていきます。
実際1250回試行では差がなかったのに125000回試行にしたら約3倍の開きができました。
A→B→C→・・・と順番に実行することを直列プログラムといい、
AとBとCと・・・を同時に実行することを並列プログラムと呼びます。
マルチスレッドプログラミングとは並行異世界プログラミングであり、
異世界が複数の処理を同時に行っています。
シングルスレッドは世界は1つしかないので、複数の処理を順番にやっていくしかないのです。
素数生成より端的にマルチスレッド効果が確認できる題材は魔方陣自動生成プログラムです。
4次魔方陣なら16スレッドプログラミングになり、
生成個数を増やすならほぼ16倍になることが期待できます。
5次魔方陣なら25スレッドプログラミングになり、20倍程度はいくと思われますが、
さすがに、25倍にはなりません。
理由は、物理CPUの個数と論理CPUの個数が私のパソコンは前者が6個(6コアと言います)、後者が12個です。
論理CPUも分身の術の一つです。
物理CPUが分身の術を使い2個分の仕事するのが論理CPUです。
ですから、私のパソコンでは理論的には12スレッドで最大化します。
16スレッドにするとCPUへの負荷が大きくなり、少し減速してしまいますが、
それでも扱っている数字が1から16ですから、
CPUへの負担は小さく大きくは減速しません。
ですから、約16倍の高速化は期待できます。
しかし、5次魔方陣の25スレッドだと最大化できるスレッド数の2倍になり、
CPUへの負荷が大きくなり25倍よりはかなり小さくなると思われますが、
16倍よりは上になると予想できます。
ですから、以降の課題は魔方陣自動生成のマルチスレッド化ということになります。